Welcome to my portfolio
UW iSchool MLIS 2013 Candidate
About Me
Introduction
 Hello and welcome! I’m Meredith Slota. I’m a data nerd, a research scientist, and a veteran rollergirl with the Rat City Rollergirls. I am also a Master of Library and Information Science candidate at the University of Washington with experience in scientific research and interests in information architecture, data services, open data, and more. This is my professional portfolio documenting my work and professional goals in information science.
Hello and welcome! I’m Meredith Slota. I’m a data nerd, a research scientist, and a veteran rollergirl with the Rat City Rollergirls. I am also a Master of Library and Information Science candidate at the University of Washington with experience in scientific research and interests in information architecture, data services, open data, and more. This is my professional portfolio documenting my work and professional goals in information science.
Professional Interests
I’m interested in data of all kinds, from meaningful save-the-world questions and working for the greater good to bar trivia night with no-Google-rules. I have more than ten years of experience in non-profit biomedical research, wrangling giant data sets and trying to figure out what it all means, all with the end goal of making the world a better place. I’m a unicorn of the science world: a geek at heart who also loves working with people. I’m fascinated by what can be accomplished by people with ideas, creativity, and motivation. I love solving problems and figuring things out, and building better data-driven solutions for people to actually use. If you’d like to learn more (or hire me!), please peek at some of my projects, visit my resume, and contact me to say “Hello!”.
You can also download my personal statement [.pdf] for the long version, but the short story is this:
I like data, and I like people. I play nice with both.

Mary Gates Hall
Mary Gates Hall, home of the iSchool. Photo by wonderland.
Data Modeling | Visualization
Metadata design | XML/XHTML | Database Design | Data Analysis and Statistics
Data Modeling for Knitters: XML/HTML Thesaurus
Annotated data stored in XML files is usable and well-organized — the data has meaning and context. But while XML annotation makes the data work, bare XML is not exactly end-user-friendly (unless the end-user is a semantic web data processing engine). Combining XML instances (the raw data) with schemas (the rules) and XML transforms that “dress up” the data in a fancy HTML/CSS skin results a data-driven website that pulls live from your well-organized data. To demonstrate my understanding of these concepts, I built a fully-functional thesaurus [.html] showing relationships between knitting-related terms.
I’ve included the code used to build the thesaurus (.xml, .xsd, .xsl, .css) [.zip]. Note: for the purpose of the assignment, we were provided with a CSS file to use; to view examples of my HTML/CSS design skills, please visit the website development section of my portfolio.
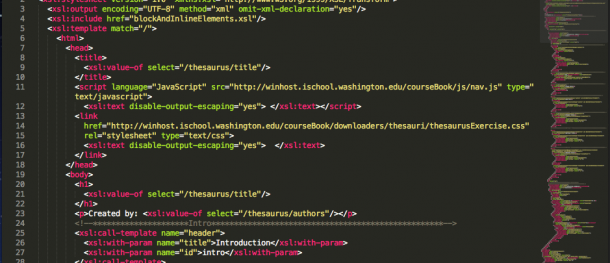
XML Data Modeling
XML-based thesaurus for INFX 542, screenshot of code for instance.
Showing (Off) Your Research: Data Visualization Tools
As a research data analyst, one of the larger challenges is explaining your data to someone else, especially if your data is a giant spreadsheet or a complicated statistical analysis. I have developed a deep interest in data visualization as a discipline because I think it can help people make sense of data in a more fundamental way. As humans, we process visual information faster and more unconsciously than words or numbers: data visualization can help users internalize the story told by the data in a completely different way, and I am excited to learn more about this field.
I created an Introduction to Data Visualization Tools presentation for the Research Commons Graduate Workshop Series with my colleagues Anna Shelton and Eli Gandour-Rood. The presentation was designed to introduce graduate students to the goals and purposes of data visualization as well as a variety of tools to suit their needs. You can download our data viz resources handout [.pdf] or view the full presentation via Adobe Connect.
In the future, I intend to develop my expertise in data visualization, including the dynamic generation of data visualizations from code combined with raw data, using the resources we presented.
Seattle Band Map Ontology: Mapping Music
Ontology development using OWL/RDF data modeling can help make human knowledge machine readable, and more functional to human users as well. Linked data can be combined with data visualization, above, to create truly dynamic and exciting data-driven websites and powerful data analyses. I am excited about data modeling using ontology development, and am practicing my skills on small projects.
I used the Seattle Band Map Project as the basis for an OWL/RDF ontology, developed using TopBraid Composer to define classes and relationships between data that could be usable in a semantic web application. The presentation of version 1.0 of this ontology is below, and the ontology itself can be explored on Stanford University’s WebProtégé. This ontology could be used to improve the data visualization behind the existing website by making connections more visible and by allowing relationships to grow via crowd-sourced data entry using their existing data collection form rather than manual database editing.
Information Architecture
User Needs, Taxonomy, and Wireframes | Projects in Website and Database Design
Why Information Architecture?
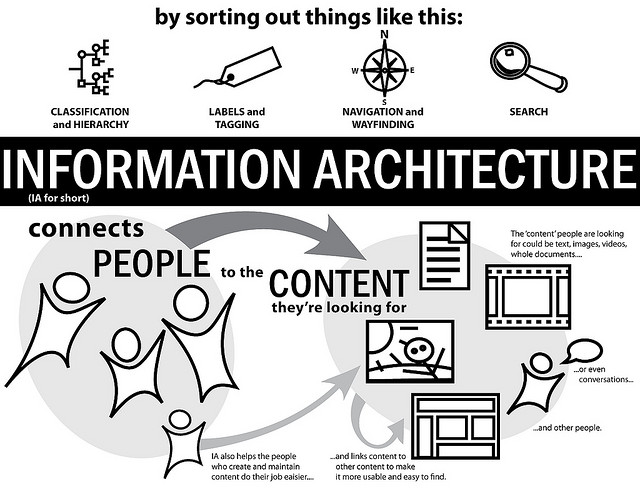
Photo by murdocke23.
Data is inherently only useful in a known context: “raw” data can be analyzed but “naked” data, without any contextual information or associated metadata, is just a pile of bytes taking up space. Information architecture provides structure to this content, whether it’s data stored in a database or articles on a website. More than that, however, information architecture is used to make information usable.
The projects below demonstrate my interest and experience in this field, and range from database module development to full website redesign, showing how information architecture can be applied to problem-solving in different contexts.
Projects
Website Redesign: Project for INFX 598
This experience demonstrates my skills with UX/IA work at a conceptual and user-centered level and showcases my technical skills at putting this conceptual knowledge into practice.
- Homepage Redesign for Better User Engagement
The homepage wireframe showing a featured menu, something that the Foodie Haven users like and that drives traffic to both products and relevant educational content like recipes. - Faceted Search Page for Users
The redesigned search page leverages item metadata and faceted search to help users find exactly what they are looking for as well as other relevant content that might be useful. - Linking Products with Content for Better Usability
A sample product page, showing both relevant item metadata which was previously unavailable, as well as user-generated content such as product reviews.
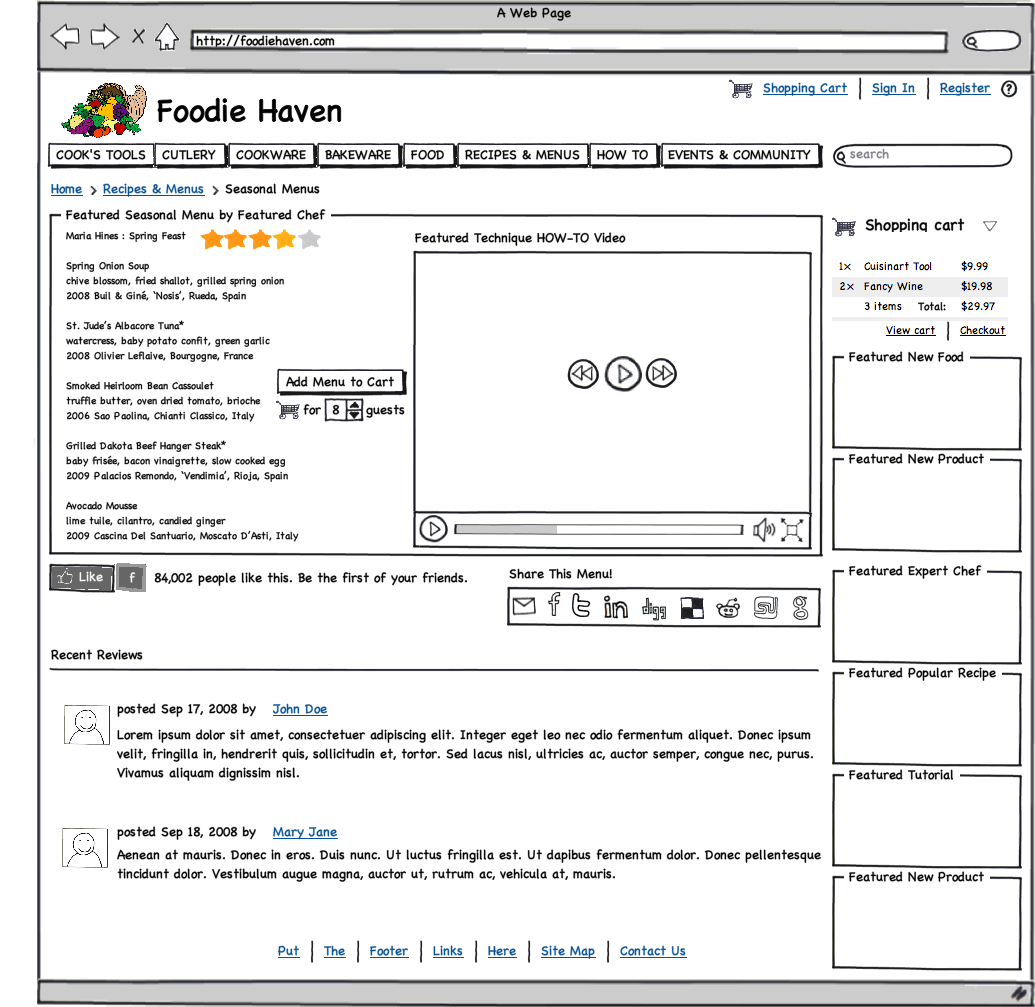
HOME PAGE
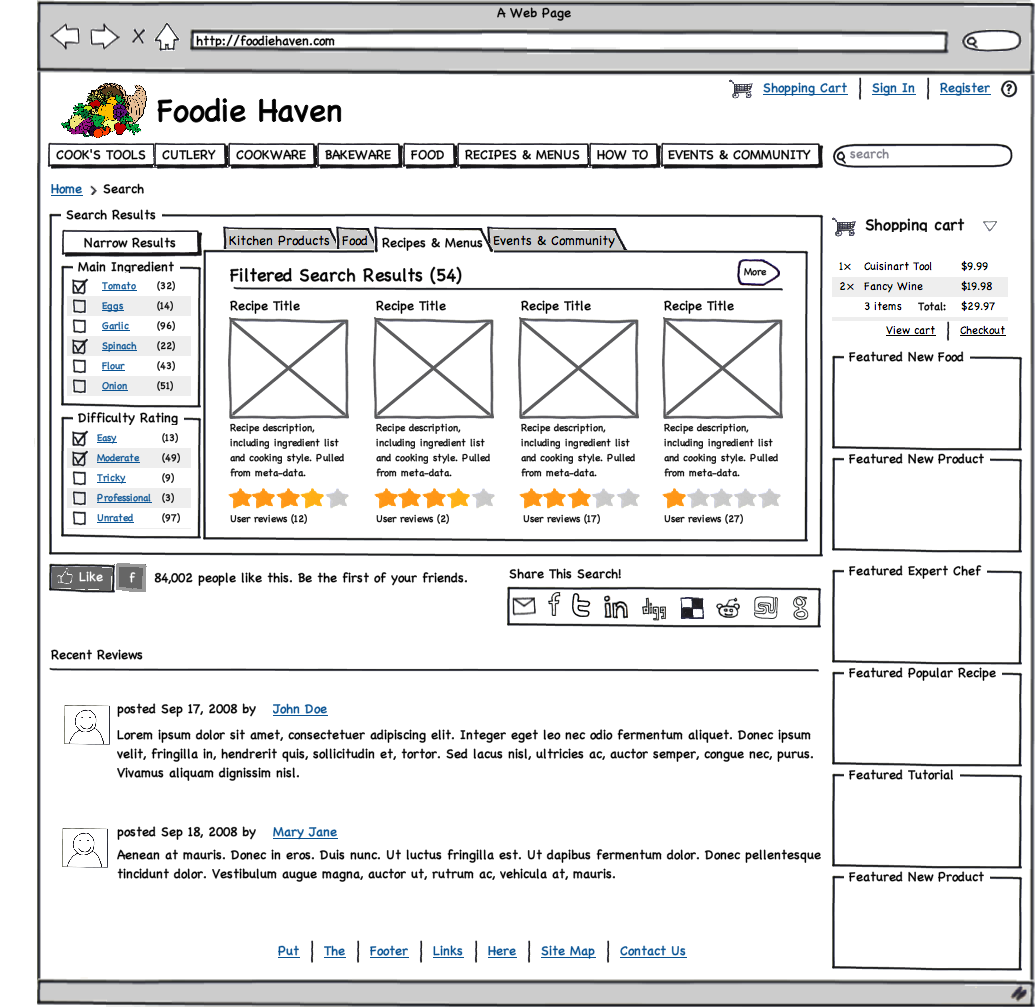
FACETED SEARCH

PRODUCT PAGE
Database Module: ELISPOT Data Tool for Research Data Management
As a research scientist, I generate mountains of data that, if left unattended, scurry off into the dark and disappears into the post-publication ether, simply because I have completed a project and moved on. The data isn’t lost, it’s just not findable by other researchers. One such example of this is data from a high-throughput immunological experiment called an “ELISPOT“, which measures immune responses to antigen stimulation. This is incredibly useful data, but was typically generated on a per-study basis, published, and then ignored: either as individual files on the server (best case), hundreds of printed pages in paper binders (ugh), or completely missing (worst case).
As an information professional, this frustrated me, and I set about designing a data tool to solve this problem. I examined the information flow from end-to-end: assay set-up, laboratory notebook documentation, assay raw data, analyzed assay results, and finally, a complete publication dataset. I designed an MS Access database module for our existing database that captured the raw data in a user-friendly format, performed basic data analysis calculations using a standardized and documented method, and created useful raw data queries that could be easily analyzed in bulk using PivotTables to create final datasets.
The final product was presented at the Society for Immunotherapy of Cancer (SITC) National Meeting in 2010; the abstract is available here: SITC abstract – ELISPOT software tool [.docx] We also released the module as an downloadable product for academic and non-profit research groups at the same time, an open-source alternative to the proprietary software currently available, which is out of reach for many small research groups as it is only available bundled with extremely expensive hardware.
Website Development
Projects and Clients: Examples
Making Sense of Code
I am a self-taught web developer who learned the basics out of sheer curiosity. I love building things, and HTML code was just another way to bring my creative visions to life. As the Internet has grown from tiny text-based bulletin boards to a dynamic and engaging global life-force of its own, I have tried to keep pace, learning advanced HTML, CSS, PHP, a bit of JavaScript, and XML/XHTML. While not a trained computer programmer, reading code makes sense to me in a way that I deeply enjoy but cannot fully explain. The following projects demonstrate my ability to develop for different contexts and user needs, considering the back-end needs and the front-end user experience at the same time.
Projects and Clients
Netherlands Exploration Seminar
CLICK FOR FULL-SIZE
Yelp API
To refer future travelers to places we’d visited, I used the Yelp API to design my own display and call live data from the Yelp.com database for use within the site. This used my data modeling skills as well as my web development skills, and it made for a more cohesive user experience than simply linking to different hotel or restaurant websites.
View Live Site This site was built using WordPress with HTML/CSS/PHP.Puja Parakh Photography

CLICK FOR FULL-SIZE
![]() Puja Parakh is an accomplished photographer with a loyal blog following. Her original blog was built in 2005 using a content management system called PixelPost, designed for photobloggers. She ran into technical difficulties when her original database ran out of space, and she enlisted me to install a new, larger database and migrate her existing website into a new content management system that would allow for greater social engagement with her fans.
Puja Parakh is an accomplished photographer with a loyal blog following. Her original blog was built in 2005 using a content management system called PixelPost, designed for photobloggers. She ran into technical difficulties when her original database ran out of space, and she enlisted me to install a new, larger database and migrate her existing website into a new content management system that would allow for greater social engagement with her fans.
New Content Management System
I choose WordPress as a content management system, as it has an easy-to-use admin interface and can be easily upgraded with plug-ins for added functionality. Migrating the data required writing custom XML-code to export the existing data intact, in a format that WordPress could easily import. I relied on my data modeling skills to ensure that the XML file was complete and compatible, and was able to migrate all 1200+ blog entries and images with minimal difficulties.
New Site Design
Puja wanted to showcase her growing business and satisfied clientele while also maintaining her daily blog in a separate space. The design she chose has static pages which showcase a curated body of work, while the blog page is more informal and allows her to interact with her followers via comments and social links. I used my experience with information architecture to analyze her needs and design the site appropriately.
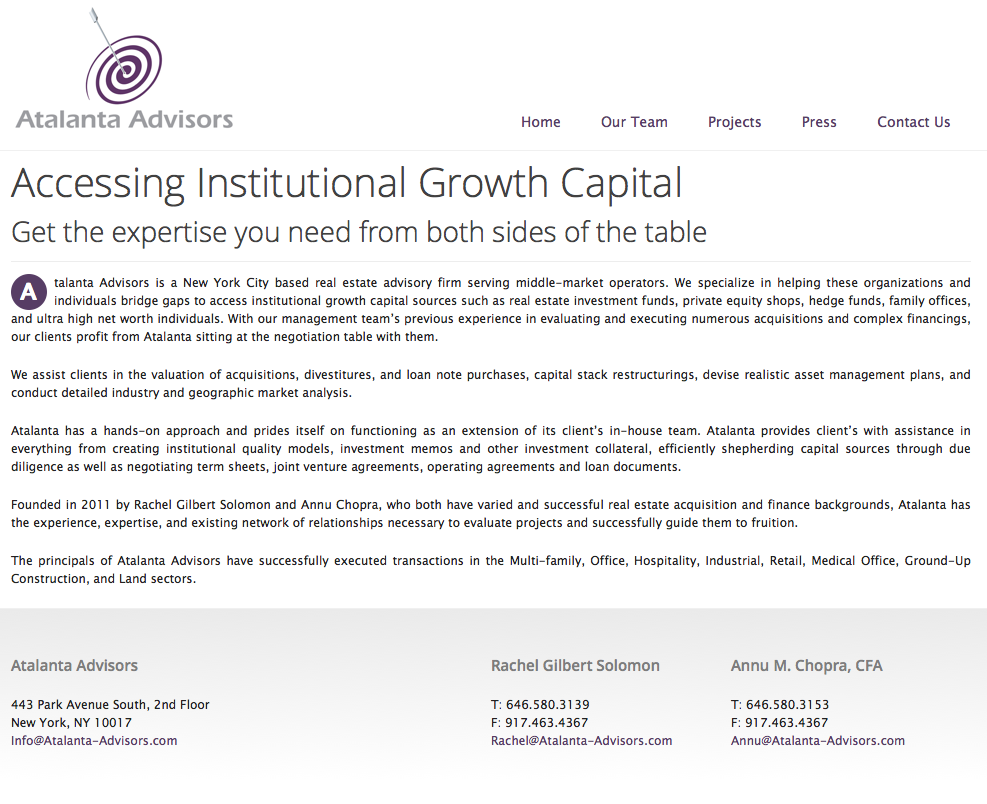
View Live Site This site was built using WordPress with HTML/CSS/PHP.Atalanta Advisors
CLICK FOR FULL-SIZE
![]() Atalanta Advisors is a New York City-based real estate advisory firm that specializes in helping organizations and individuals bridge gaps to access institutional growth capital sources.
Atalanta Advisors is a New York City-based real estate advisory firm that specializes in helping organizations and individuals bridge gaps to access institutional growth capital sources.
They needed a simple, classic website to showcase their professional accomplishments, but did not plan on updating their site themselves so did not need nor want a full content management system like Drupal or WordPress installed. Instead, I used PHP-includes to create template portions of the site (headers, footers, etc.) which were published on every page site-wide, allowing me to update the back-end efficiently while the changes propagated site-wide.
View Live Site This site was built using HTML/CSS/PHP.Rat City Rollergirls

CLICK FOR FULL-SIZE
![]() The Rat City Rollergirls are Seattle’s premier women’s flat track roller derby league. Founded in 2004, their website was born shortly after that, with the same D.I.Y. ethos. As the league grew, they added pages and content until eventually the site became unwieldy and hard to navigate (for users) and hard to maintain (for the organization itself).
The Rat City Rollergirls are Seattle’s premier women’s flat track roller derby league. Founded in 2004, their website was born shortly after that, with the same D.I.Y. ethos. As the league grew, they added pages and content until eventually the site became unwieldy and hard to navigate (for users) and hard to maintain (for the organization itself).
New Content Management System
They needed an easy-to-use content management system to lower barriers to editing: the previous site was hand-coded which limited the number of people who could successfully add content, and as an all-volunteer organization, they needed all the willing hands they could get. We decided to implement a WordPress site for this reason.
Site Branding and Improved Navigation
They also needed a complete site redesign with improved information architecture and branding that reflected the league’s style and mission. While a local design firm, Eben Design, created a style that reflected the league’s personality, I led the content inventory and designed a fan-friendly information architecture based on our most popular links and a fan survey about why they visited the website. Noting a significant increase in website hits on the day prior to and the day of games, we made event information a priority, including ticket sales, directions to events, and frequently asked questions about attending our events. The new site launched in 2010 and has seen a dramatic growth in site visits and customer satisfaction with the site experience.
View Live Site This site was built using WordPress with HTML/CSS/PHP.Intellectual Freedom | Open Data
Information as a Human Right | Open Access and Open Data Driven Collaboration
Information in Social Context: Public vs. Private
Information always has context, but what happens when the context is us? I explored the intersection of public and private and considered the social context of visual information, namely photographs taken in public places (sometimes called “street photography“). The case in question is Nussenzweig v. DiCorcia, in which a street photographer, Philip-Lorca diCorcia, was sued for photographing Erno Nussenzweig without consent. The existence and sale of the photographs, Nussenzweig claimed, violated his privacy rights. The court ruled in favor of DiCorcia.
… Clearly, plaintiff finds the use of the photograph bearing his likeness deeply and spiritually offensive. The sincerity of his beliefs is not questioned by defendants or this court [but rather illustrates] the extent to which the constitutional exceptions to privacy will be upheld, notwithstanding that the speech or art may have unintended devastating consequences on the subject, or may even be repugnant. They are […] the price every person must be prepared to pay for in a society in which information and opinion flow freely.
My analysis of this case and presentation shown above demonstration my ability to communicate complex concepts clearly using visuals to add emphasis. The slideshow uses very little text and was given in the “lightning talk” style which enforces a strict time limit, forcing speakers to present with brevity without skipping information.
Intellectual Freedom in Libraries: Social Justice in Education
As part of a course focused on intellectual freedom, we were asked to find and analyze a case of a challenge to intellectual freedom, including developing a plan to address this challenge.
Imagine that you are the librarian charged with addressing the challenge you located through your search of the literature. Analyze the challenge, looking for ways to defuse the conflict while also providing a workable solution for all parties involved. Utilize the readings from the class or other relevant readings to craft a plan for addressing the challenge. … Remember your commitment as a librarian to uphold the principles of intellectual freedom.
I researched a case involving the Arizona school district and their ban on ethnic studies. The Case Challenge Analysis – Arizona Bans Ethnic Studies [.pdf] shows my background research, analysis of the stakeholders and legal issues at hand, and (spoiler alert!) arguments against the Arizona school district’s position, emphasizing the need for libraries to take a strong role in protecting access to this kind of information as a social justice issue. This demonstrates my strong beliefs in access to information as a human right, including education in “dangerous” subjects.
Linked Data and Google Refine
INFX 532 project placeholder: leveraging publicly available data to drive collaboration, publish data transparently but securely. Project due day is June 10th; I will add the files as they become available.
Professional Development
Professional Goals and Future Educational Opportunities
Goals and Interests
Summary
My area of professional interest is data: data management, information architecture, linked data, data analysis/statistics, and metadata/API development (XML and other systems). I am interested specifically in positions working with open data or positions that leverage my background in clinical research, including oncology research, or my experience in web development or statistical programming. My long-term interests involve learning more about data science and creating data visualizations at advanced levels.
Short-Term Goals
My immediate goals focus on putting the theoretical foundations of information science into practice using the education and technical skills gained from my MLIS program.
- Develop my own code-based data visualization to publicly showcase my skills in this area
- Publish my open-source database module for ELISPOT data on GitHub to increase exposure and access to this tool
- Obtain a new professional position in the areas described above
Long-Term Goals
In the future, I’d like to learn more about data science techniques that require computer programming (Python, Hadoop, etc.) and about combining these big data analytical techniques with data visualization (d3, R for data viz, etc.). I intend to pursue the following educational opportunities to continue advancing my skills:
Data Science
- http://www.jblumenstock.com/teaching/course=infx598: This introduction to data science class filled up so quickly that I was unable to take it before graduation, but I intend to work my way through the coursework individually
- http://www.pce.uw.edu/certificates/data-science.html: If the class above goes well, I intend to pursue the University of Washington’s certificate program in data science, which covers introductory material and also hands-on technical training in methods more formally
- https://www.coursera.org/courses?search=data%20science: There are open courses available through Coursera on a variety of data science topics, including machine learning and specific tools like Hadoop, etc. (including some from UW professors, like this one: https://www.coursera.org/course/datasci) to continue in this direction
Programming
- http://learnpythonthehardway.org/: While I have experience with Perl and have begun learning Python, I would like to increase my usage and expertise in this language.
Data Visualization
- http://alignedleft.com/tutorials/d3/: I intend to work my way through some of these tutorials this summer to accomplish short-term goal #1, but to continue exploring this tool for future use
Nerds for the Greater Good
I believe strongly in the ability of data to do good: I want to unite with other nerds and use our collective nerd powers to solve problems. I have always worked in academic or nonprofit research and deeply enjoy teaming up with smart, dedicated people who just want to help. That’s one reason I returned to the University of Washington for my Masters in Library and Information Science: I can do more and better work by expanding my reach beyond the research lab and into the larger world of global information, especially in the context of open knowledge. I am an advocate for breaking down the research “data silo” by distributing open-source data management tools, publishing in open-access journals, and bringing raw data online for easy access, including data visualization for better communication.
Making the world a better place seems like a pretty good endgame, and whether I help develop a cancer treatment that saves lives or help make information available and easily usable to the next generation of researchers and learners, I am in. If this sounds like someone you’d like to work with, please contact me.
Resume | C.V.
Education, Professional Experience, and Publications
I like data, and I like people. I play nice with both. I love figuring things out, and coming up with better solutions to frustrating problems. I believe in the power of connections, especially with data, and I love finding the story and communicating the results. I am currently working on my Master of Library and Information Science at the University of Washington, with a decade of research and data analysis under my belt.
Education
University of Washington – Seattle, WA
Masters in Library and Information Science
Fall 2010 – Present
- Concentrations: information architecture and data science
- Delivered a site redesign proposal based on a case study of a retail website, focusing on user needs assessments, information organization best practices, and aesthetic appeal. Developed wireframes to present proposal to stakeholders.
- Selected for highly competitive UW Information School “Dutch Designs” program, an international seminar based in the Netherlands, focused on research methods and design.
- Researched and delivered a successful grant application for Casa Latina, resulting in $20,000 to fund a computer lab to provide essential computer literacy training and access to technology for their members.
- Coded fully functional XML/XHTML-based taxonomy/thesaurus using superordinate/subordinate hierarchical relationships between terms, use and use-for examples, and scope notes.
The MLIS core curriculum emphasizes the theoretical foundation necessary to make your education one you can use to build on throughout your career. Students will use their understanding of systems design, information literacy, information architecture, usability and similar disciplines to make the information environments we interact with every day more useful and useable. Empowered to adapt to a growing and changing field, you will learn to use information as a tool for transformation in your personal and professional lives.
Along with the core curriculum, I chose to focus on information architecture, data modeling and system interoperability, web development, and statistics. A brief listing of my elective coursework is below, and you can explore some of my work from those courses above in the “Projects” section. Course descriptions are from the University of Washington course catalog.
| Course | Title |
|---|---|
| INFX 501 | Concepts in Algorithmic Thinking for Information |
| Presents programming concepts in the context of information science including the concepts of the algorithm, data storage, expressions, syntax, logic, objects, commands, and events. Introduces the algorithmic manipulation of information objects, and the mindset and methods of computer programming and application development. | |
| INFX 502 | Database Concepts for Information Professionals |
| Introduces the terminology and concepts of working with relational database management systems. Emphasizes working with tables and extracting information from data using Structures Query Language (SQL) commands and tools. | |
| INFX 503 | Website Design Concepts for information Professionals |
| Introduces the context and construction of websites presenting an integrated understanding of web design principles, information behavior, and technical skills. Emphasizes the roll of markup in information display and organization, the development of large sites, web strategy, and site construction. | |
| INFX 505 | Project Management Basics for Information Professionals |
| Introduces the terminology, concepts, and skills used in working with project management and project management software. Emphasizes developing, refining, and monitoring work schedules using software tools. | |
| INFX 531 | Metadata Design | Design principles of metadata schemas and application profiles – implementation of interoperable application profiles using XML technology. Focuses on achieving syntactic and semantic interoperability among diverse metadata schemas and application profiles. |
| INFX 532 | Ontology Design |
| Studies semantic interoperability among different metadata schemas and ontologies. Elaborates on concepts and technology related to Topic Maps, RDF Schema, and Web Ontology Language (OWL) to achieve advanced and semantic data modeling of complex data that exist in the real world. | |
| INFX 542 | Information Structures Using XML |
| Introduces the concepts and methods used to analyze, store, manage, and present information and navigation. Equal weight given to understanding structures and implementing them. Topics include information analysis and organizational methods as well as XML and metadata concepts and application. | |
| INFX 598 | Information Architecture |
| Covers the key elements of Information Architecture: understanding your users’ information needs, building architectural frameworks to store information effectively, proper organizing and labeling of information for improved navigation and search, and perceiving opportunities where information architecture can increase business value. | |
| LIS 551 | Intellectual Freedom in Libraries |
| Analysis of issues related to intellectual freedom, particularly to implications for libraries and librarians. Consideration of current legal climate, conformity versus freedom in modern world, librarian as censor, social responsibility and individual freedom, intellectual freedom of children, prospects for future. | |
| LIS 579 | Special Topics in Research: Exploration Seminar |
| In fall 2012, I joined a small group of iSchool students for an exploration seminar on research methods and design, which took place in the Netherlands. My reflection project on this can be found here: nex.meredithslota.com | |
| BIOSTAT 517 | Applied Biostatistics I |
| Introduction to the analysis of biomedical data. Descriptive and inferential statistical analysis for discrete, continuous, and right-censored random variables. Analytic methods based on elementary parametric and non-parametric models for one sample; two sample (independent and paired), stratified sample, and simple regression problems. | |
| BIOSTAT 518 | Applied Biostatistics II |
| Multiple regression for continuous, discrete, and right-censored response variables, including dummy variables, transformations, and interactions. Introduction to regression with correlated outcome data. Model and case diagnostics. Computer assignments using real data and standard statistical computer packages. |
University of Washington – Seattle, WA
Bachelors of Science in Cell & Molecular Biology, Chemistry
Fall 1998 – Spring 2002
- Dean’s List, Advanced Placement Scholar Award
Experience
Center for Translational Women’s Health, Tumor Vaccine Group
University of Washington – Seattle, WA
Research Scientist II | Research Data Analyst and Statistical Consultant
April 2005 – Present
- Collaborate with 40+ researchers, clinicians, and principal investigators within internationally recognized organization to develop data-driven research questions. Data mine historical data, document analysis procedures, and present results and recommendations to a variety of audiences to help inform decision-making.
- Design and develop relational database modules using Microsoft Access to manage structured and unstructured experimental and clinical data and metadata. Created and implemented information architecture and controlled vocabularies.
- Define and implement data standards and processes across multiple organizational groups, resulting in improved communication and analysis efficiencies.
- Develop and launch data visualization tools (Excel, GraphPad Prism, Tableau) to present customized views for stakeholders at all levels of the organization.
- Provide statistical analysis (Stata, R) of immunological monitoring data from clinical trials for breast and ovarian cancer.
- Collaborate with clinicians and principal investigators across four major research centers on study design to ensure statistical power, appropriate endpoint analysis, and proactive troubleshooting of potential pitfalls.
Rat City Rollergirls (Derby Liberation Front, All-Star Team) – Seattle, WA
Website Developer and Rollergirl
June 2004 – Present
- Launched a complete site redesign for www.ratcityrollergirls.com, one of the most popular roller derby websites in the country, including the implementation of a content management system (CMS). Site update met operational and business goals, shown by a dramatic increase in site visits to over 100,000+ per month and increased online retail sales by over 200%.
- Established project parameters, performed heuristic evaluations, wrote proposals for design work, conducted market research of competitor web sites, determined site content and content strategy.
- Implemented intuitive and navigable information architecture for content categorization to improve browsing using business intelligence from website statistics, user data, and institutional knowledge.
- Created custom dashboard using Google Analytics and visualizations for stakeholders.
- Utilize expertise in front-end development such as HTML, CSS, XML, and JavaScript to enhance user experience.
- Captained championship-winning team, Derby Liberation Front, for three years, showing leadership and sportsmanship in difficult situations.
Institute for Systems Biology – Seattle, WA
Research Scientist I
April 2001 – April 2005
- Analyzed and interpreted (J-Express, Perl) biological “big data” (microarray datasets, >100,000K data points per set) to identify gene expression patterns.
- Researched, designed, and implemented a pilot study on the feasibility of diagnosing Type I diabetes pre-clinically via serial blood draws and genome-wide expression pattern analysis.
Computer Skills
Statistics/Data
- Stata/R
- Tableau
- GraphPad Prism
- MS Access/SQL
- Excel wizard
Web/Design
- HTML/CSS/PHP/JavaScript
- CMS (WordPress, Drupal)
- Google Analytics
Programming
- Perl/Python
- XML/XHTML/OWL/RDF
Publications & Abstracts
- Slota M, Kuan LY, Auci D, and Disis ML. (2012) Identification of Immunogenic Epitopes from Cancer Stem Cell Antigens for the Design of Multi-Epitope Th1 CD4+ T Cell Vaccines Against Breast Cancer. Society for Immunotherapy of Cancer (SITC) 2012 Annual Meeting.
- O’Donoghue E, Slota M, Auci D, and Disis ML. (2012) ELISA Tool: An Open-Source Relational Database Module for ELISA Experimental Data. Society for Immunotherapy of Cancer (SITC) 2012 Annual Meeting.
- Auci D, Slota M, Higgins D, Childs J, Salazar L, Coveler A, and Disis ML. (2012) Effect of Age on Immunity and Responses to Breast Cancer Vaccination. Society for Immunotherapy of Cancer (SITC) 2012 Annual Meeting.
- Gad E, Rastetter L, Slota M, Koehnlein M, Dang Y, Treuting P, and Disis ML. (2012) Natural history of tumor growth and metastasis in common spontaneous murine breast cancer models. Society for Immunotherapy of Cancer (SITC) 2012 Annual Meeting.
- Slota M, Lim JB, Dang Y, and Disis ML. (2011) ELISpot for measuring human immune responses to vaccines. Expert Review of Vaccines, 10(2):299-306. PubMed #21434798.
- Disis ML, Wallace D, Gooley T, Dang Y, Slota M, Lu H, Coveler A, Childs J, Higgins D, Fintak P, delaRosa C, Tietje K, Link J, Waisman J, and Salazar L. (2009) Concurrent Trastuzumab and HER-2/neu-Specific Vaccination in Patients with Metastatic Breast Cancer. J Clin Oncol. 2009 Oct 1;27(28):4685-92. Epub 2009 Aug 31. PubMed #19720923.
- Goodell V, dela Rosa C, Slota M, MacLeod B, and Disis ML. (2007) Sensitivity and specificity of tritiated thymidine incorporation and ELISPOT assays in identifying antigen specific T cell immune responses. BMC Immunol. 2007 Sep 12;8:21. PubMed #17850666.
- Broussard E, Coveler A, Kim R, Rastetter L, Gad E, Slota M, Childs J, Higgins D, and Disis ML. (2011) Characterization of colon cancer associated antigens which would be key therapeutic targets in the prevention of disease relapse or progression. AACR Molecular Therapeutics Meeting 2011.
- Slota M, O’Donoghue E, Tietje K, and Disis ML. (2009) A Novel Software Application for ELISPOT Data Calculation, Conversion, and Quality Assurance Reporting. International Society for Biological Therapy of Cancer, Annual Meeting Proceedings; Oct. 28 – 31, 2009.
- Salazar L, Swensen R, Markle V, Coveler A, Royer B, Dang Y, Slota M, Childs J, Wallace D, and Disis ML. (2008) Phase I study of intraperitoneal (IP) denileukin diftitox in patients with advanced ovarian cancer (OC). Proc. Amer. Soc. Clin. Oncol. 2008.
- Webster D, Waisman J, Link J, MacLeod B, delaRosa C, Higgins D, Fintak P, Childs J, Slota M, Salazar L, and Disis ML. (2006) A phase I/II study of a HER-2/neu peptide vaccine plus concurrent trastuzumab. Proc. Amer. Soc. Clin. Oncol. 2006.
Contact Me
Find me elsewhere online
You can reach me directly by email at heymeredith@gmail.com or via any of the fine social media establishments below.




